The null check at 2am shouldn't need you.
Runtime errors. Auto-fixed. Tested PRs.
bugstack captures runtime errors the moment they're thrown, writes the fix, runs it through your CI, and ships the PR. The whole loop, end-to-end, under 2 minutes.
3 files max. 30 lines max. No dependency changes. That's the point.
Trusted by zero industry leaders… Yet.
If you can’t recognize any of these, we probably can’t help you.
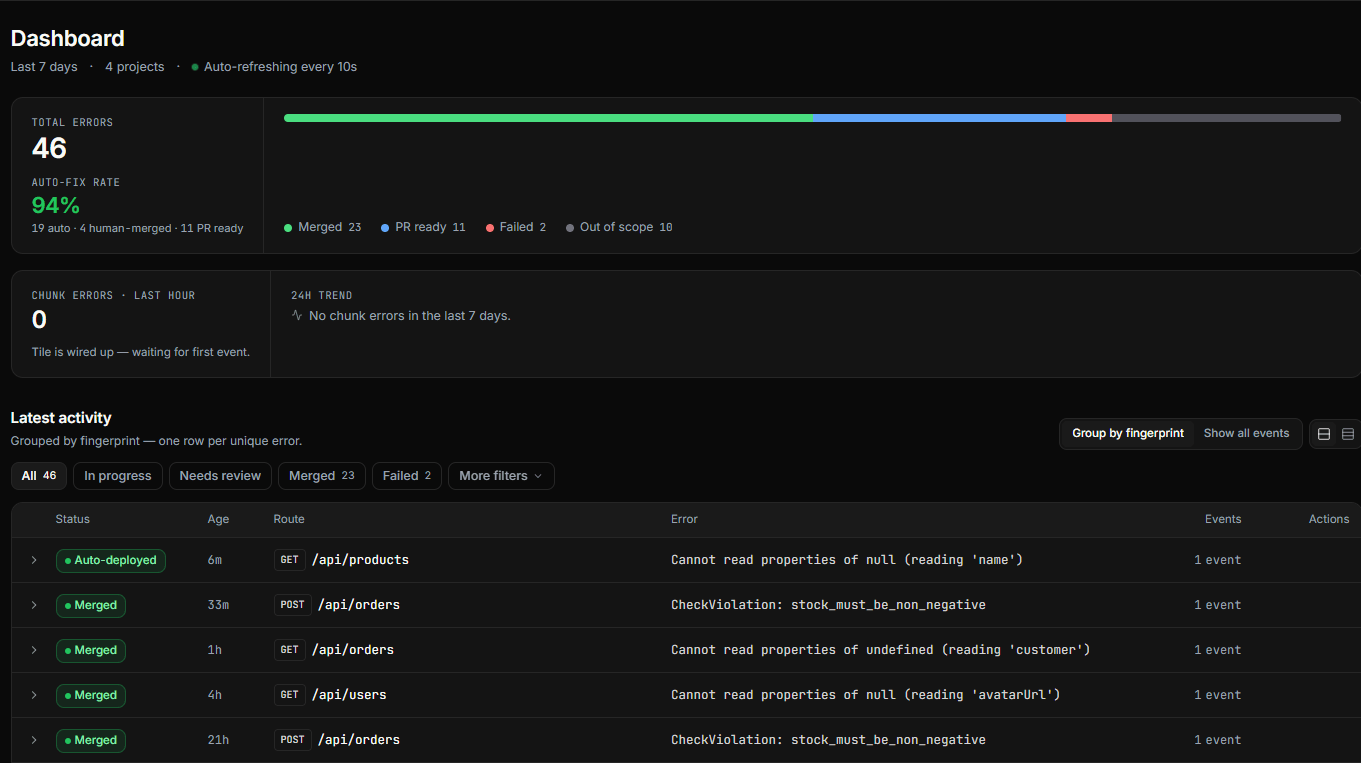
Every runtime error costs your team 30+ minutes. It shouldn't.
Here's what happens when a single production error fires today — and what it could look like instead.
Without bugstack
- Error thrown in production 0:00
- Alert fires in monitoring tool +30 sec
- On-call engineer paged +2 min
- Engineer opens laptop, reads alert +5 min
- Diagnose: find stack trace, read context +10 min
- Write fix, push branch, open PR +8 min
- Wait for CI, get review, merge +7 min
With bugstack
- Error thrown in production 0:00
- SDK captures the error +5 sec
- Stack trace analyzed, context pulled +10 sec
- Fix generated, PR opened +30 sec
- CI runs, tests pass +45 sec
- Auto-merged & deployed +30 sec
- No human needed —
Same error. Same stack. Different architecture. The difference isn't speed — it's whether a human is in the middle of a loop that doesn't need them.
One SDK. Two lines. Errors flow in with full context.
Install the SDK in your framework and production errors flow to bugstack the moment they're thrown — async, non-blocking, fingerprinted.
Async & non-blocking
The SDK captures errors on a background thread. Your API response times never change, and your users never wait on bugstack.
Fingerprinted automatically
Same error type + route + stack frame = one fingerprint. Duplicates within 24 hours increment a counter instead of re-running the pipeline.
Rate-limited by default
A flood of errors won't flood bugstack. The SDK enforces sensible ceilings so a single broken deploy doesn't DoS your fix pipeline.
of your production bugs, fixed autonomously. And we're honest about the rest.
bugstack handles stack-trace-anchored runtime errors — roughly 40–60% of production bug volume in typical SaaS codebases. Logic errors, architectural problems, and business logic bugs stay with your engineers.
What bugstack fixes well
- TypeError, null/undefined property access
- Missing or wrong local imports
- Unhandled async failures & promise rejections
- Small guard & input-shape fixes
- Local import/export/signature mismatches
- Small Next.js route-handler errors
- Python NoneType & attribute errors
- Ruby NoMethodError on nil
- Go nil pointer, index, map & type assertion panics
Partially fixable
- Logic errors that throw an exception (minimal correction possible, but domain intent may be needed)
- Runtime type mismatches (parse-only validation, no TypeScript type checking)
- External service call-site failures (can add a guard, can't fix the API itself)
- Go concurrency panics (only when the stack trace points to a small local fix)
What bugstack doesn't fix
- Silent logic errors with no thrown exception
- Architectural problems requiring redesign
- Dependency or package upgrades
- Database schema & migration issues
- Build-only failures not captured by the SDK
- Third-party/framework-only stack traces
- Errors with bad or missing stack traces
- Full agentic repo work (clone, shell, iterate)
Coverage estimate based on aggregate bug taxonomy data from Stack Overflow Developer Surveys, DORA research, and analysis across bugstack customer deployments. Read the full methodology in our 2026 Incident Response Benchmark →
Your CI is the gatekeeper. Your confidence is the lever.
Every fix runs through your existing CI pipeline before anything merges. From there, you decide: manual review via PR, or auto-merge above a confidence threshold.
CI runs
Confidence scored
94% > 85% threshold
Merge decision
Security paths → always manual
Your tests, unchanged
bugstack uses the CI pipeline you already run on every PR. No new infrastructure, no new test framework, no duplicate work.
One retry, then stop
If CI fails, bugstack gets exactly one more attempt with the failure output as context. If the retry also fails, the PR stays open for a human — no infinite loops, no wasted CI minutes.
Security paths always require a human
Fixes touching authentication, cryptography, or input sanitization can never auto-merge, regardless of confidence score. Most teams spend the first 30–60 days reviewing every fix and graduate at their own pace — the 3 AM page becomes a morning summary.
See bugstack run on your repo — live, in 20 minutes.
When the loop closes, the numbers change.
Industry benchmarks for incident response look one way when a human is in the middle of the loop — and a very different way when that loop is closed by an agent.
Mean Time to Resolution (MTTR)
Want to see these numbers on your codebase?
Stop triaging. Start shipping.
See bugstack running on your stack in 20 minutes — or start the trial and connect GitHub yourself. Either way, your first tested PR lands today.
Want the full analysis? Read our 2026 Incident Response Benchmark →